如何从 0 到 1 构建一个亚马逊竞品监控 Skills
- AI实战
- 2026-06-14
- 51热度
- 0评论
这篇算是上一篇《如何利用 MCP/CLI 与大模型实现全自动市场调研?》的实践版,上一篇我把结果拿出来讲了一遍,这篇把背后的搭建过程拆开讲清楚。
上一篇文章发出去之后,有不少读者问我:那个 HTML 市场调研报告看起来挺完整,但到底怎么让 AI 稳定输出?为什么自己用 ChatGPT 写调研报告,每次结果都不一样?
这个问题挺关键。很多人第一次用大模型做调研报告,效果都还可以。第二次再跑,结构开始变。第三次换个类目,它可能又换一种写法。你让它“专业一点”,它就开始堆概念;你让它“详细一点”,它又容易把一堆字段摊成流水账。
我的做法是:先把人的工作流程写清楚,再把确定性的部分交给脚本,把需要归纳的部分交给大模型,最后用固定模板交付。约束AI 不再临场发挥,而是按固定流程干活。
这篇就讲这件事。我们从一个很普通的亚马逊运营需求开始:我想监控几个竞品 ASIN。然后看它怎么一步步变成一个能复用、能追溯、能交付报告的 Skill。
先看结果:它最后能干什么?
先不急着讲原理,直接看成品。你对 AI 说一句:
帮我生成一份 ASIN 竞品监控报告。
它会自己往下做几件事:
- 读取你提前配置好的监控清单,包括自有 ASIN、竞品 ASIN、核心关键词。
- 调用 Sorftime CLI,把价格、销量、BSR、评论、关键词、Listing 等数据拉回来。
- 拿今天的数据和昨天的快照做对比,找出降价、上券、标题调整、关键词排名变化这些事件。
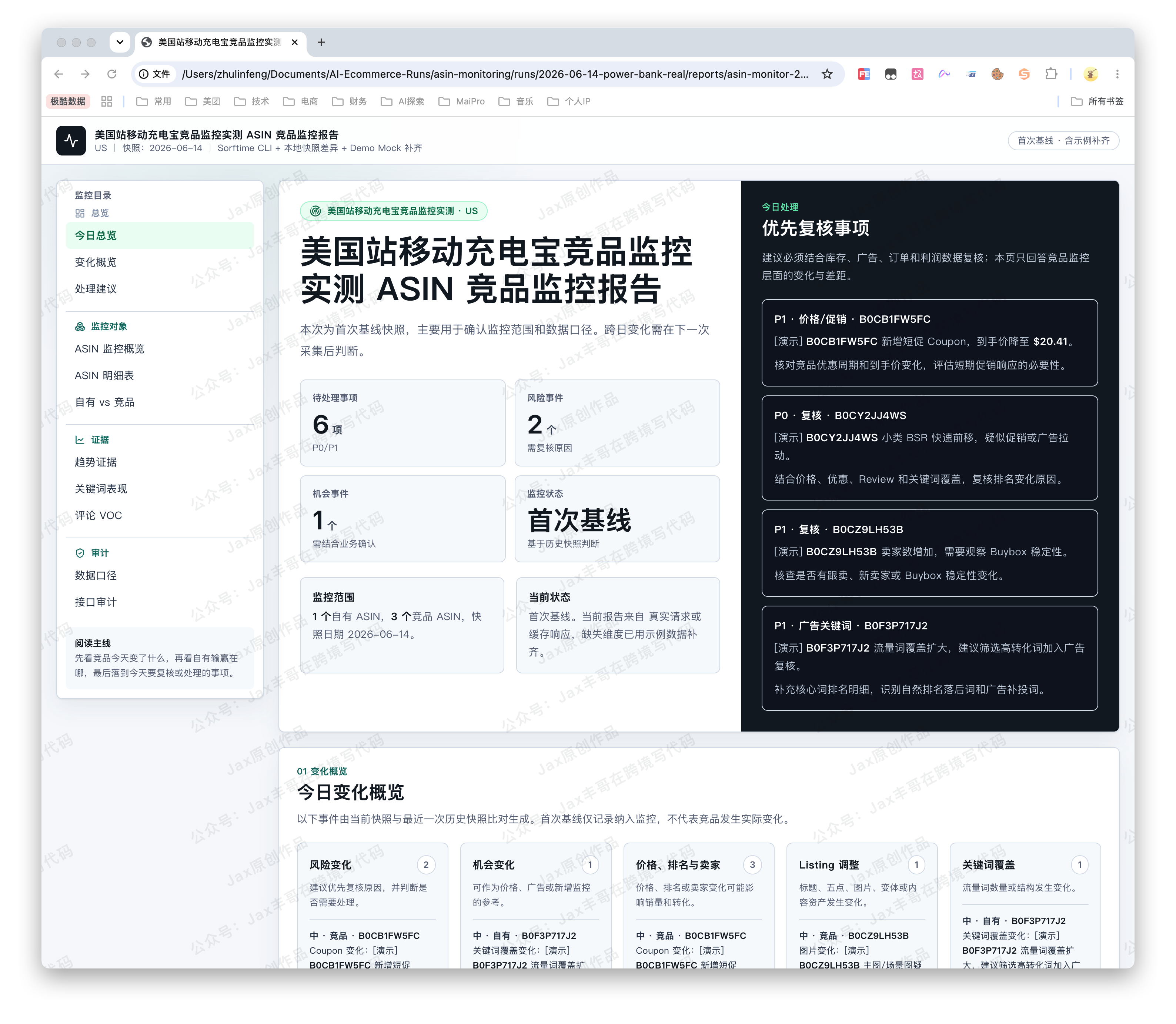
- 最后生成一份 HTML 报告。报告里有目录、图表、事件时间线,也有接口调用审计。
注意:图片仅为Demo展示,部分图表为Mock数据
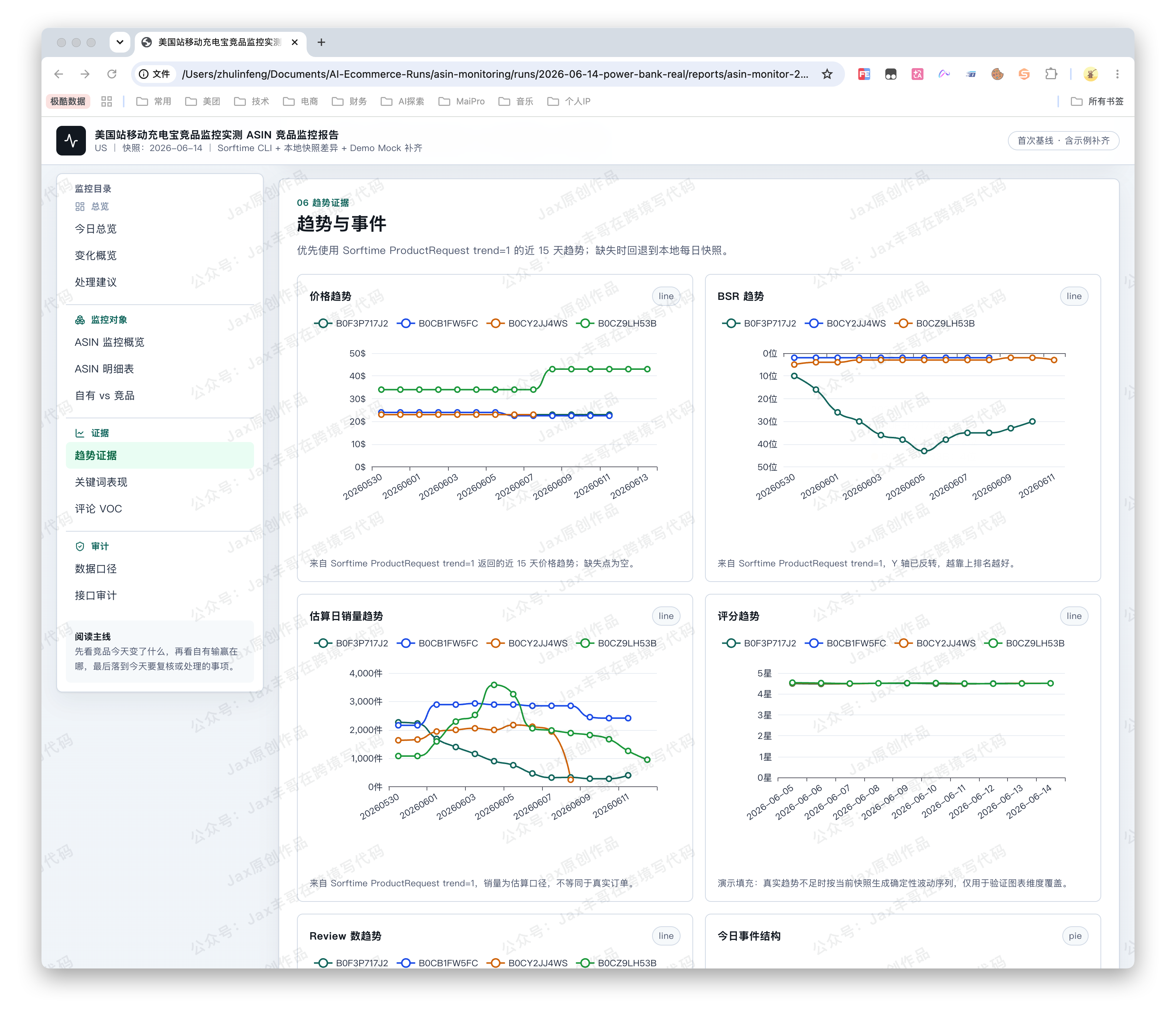
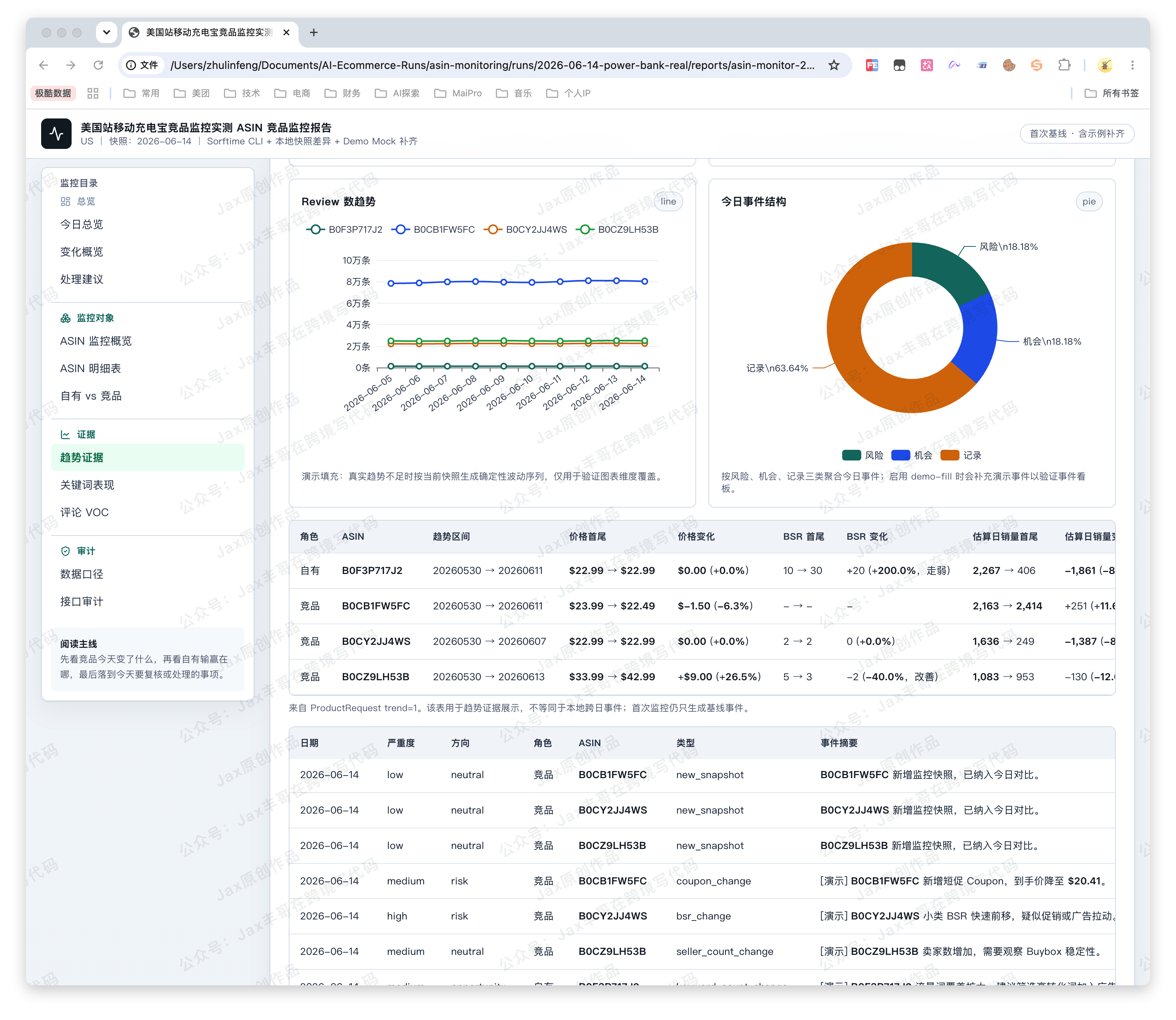
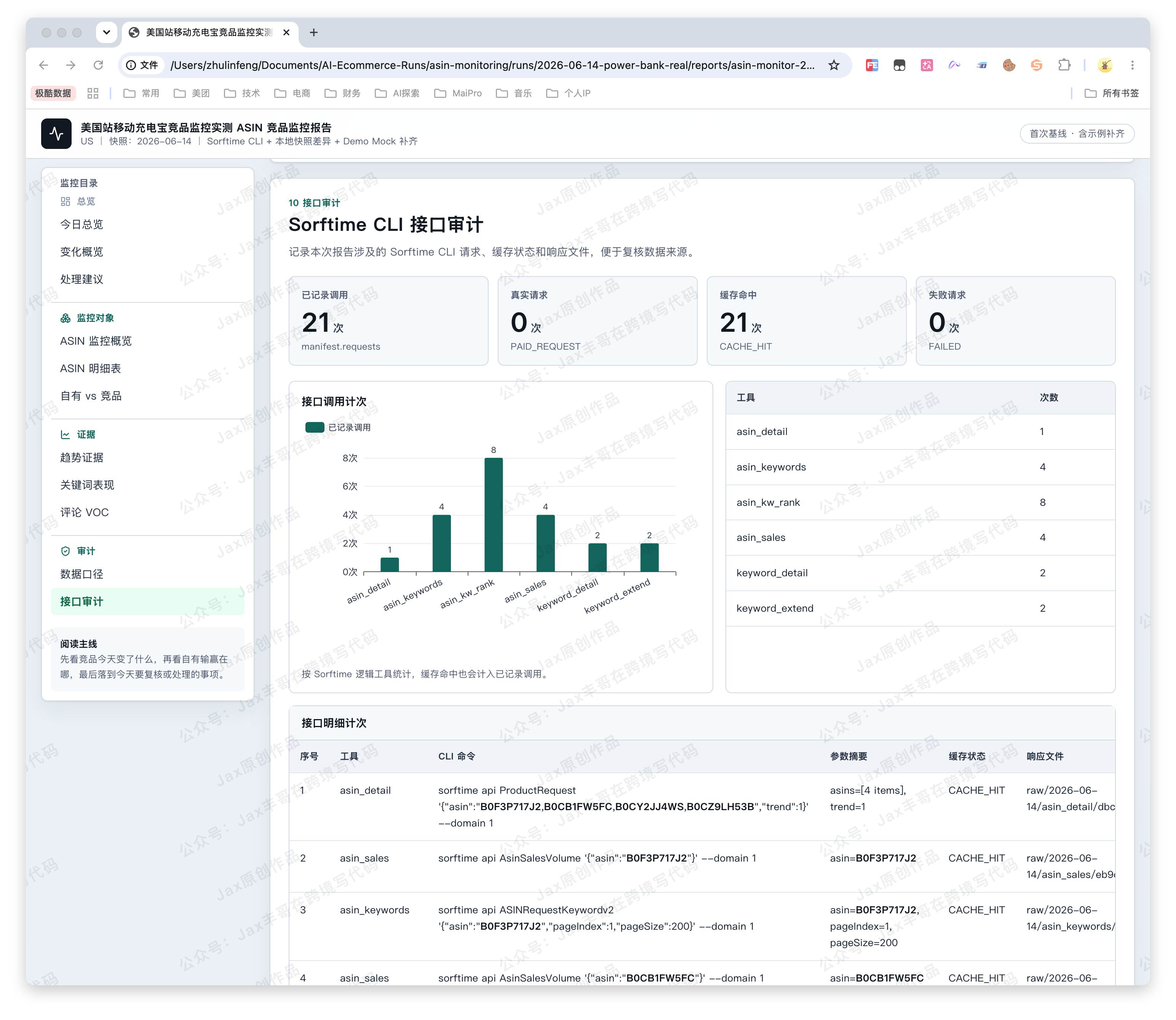
它不是“帮我写一篇分析”。
更准确地说,它是帮运营把每天那套重复动作跑完,然后把结果整理成一份能开会、能归档的报告。
人工盯盘当然也能做。但人工盯盘有一个很现实的问题:看得越久,越依赖记忆。昨天竞品有没有降价?上周 Coupon 是什么时候上的?这个 ASIN 的 BSR 是突然变好,还是慢慢爬上来的?这些细节靠脑子记,很容易漏。
Skill 要解决的不是“AI 比运营聪明”,而是“让重复动作不要一直靠人肉执行”。
一、先把业务问题说透
很多人写 Skill,一上来就写脚本、写命令、写调用链。我以前也容易这样。后来发现,越是这样写,后面越容易失控。
原因很简单:你还没说清楚业务边界,工具就已经开始替你决定结果了。
所以我一般会先把 Why、What、How 写出来。不是为了显得方法论完整,而是为了防止自己把一个小需求做成大杂烩。
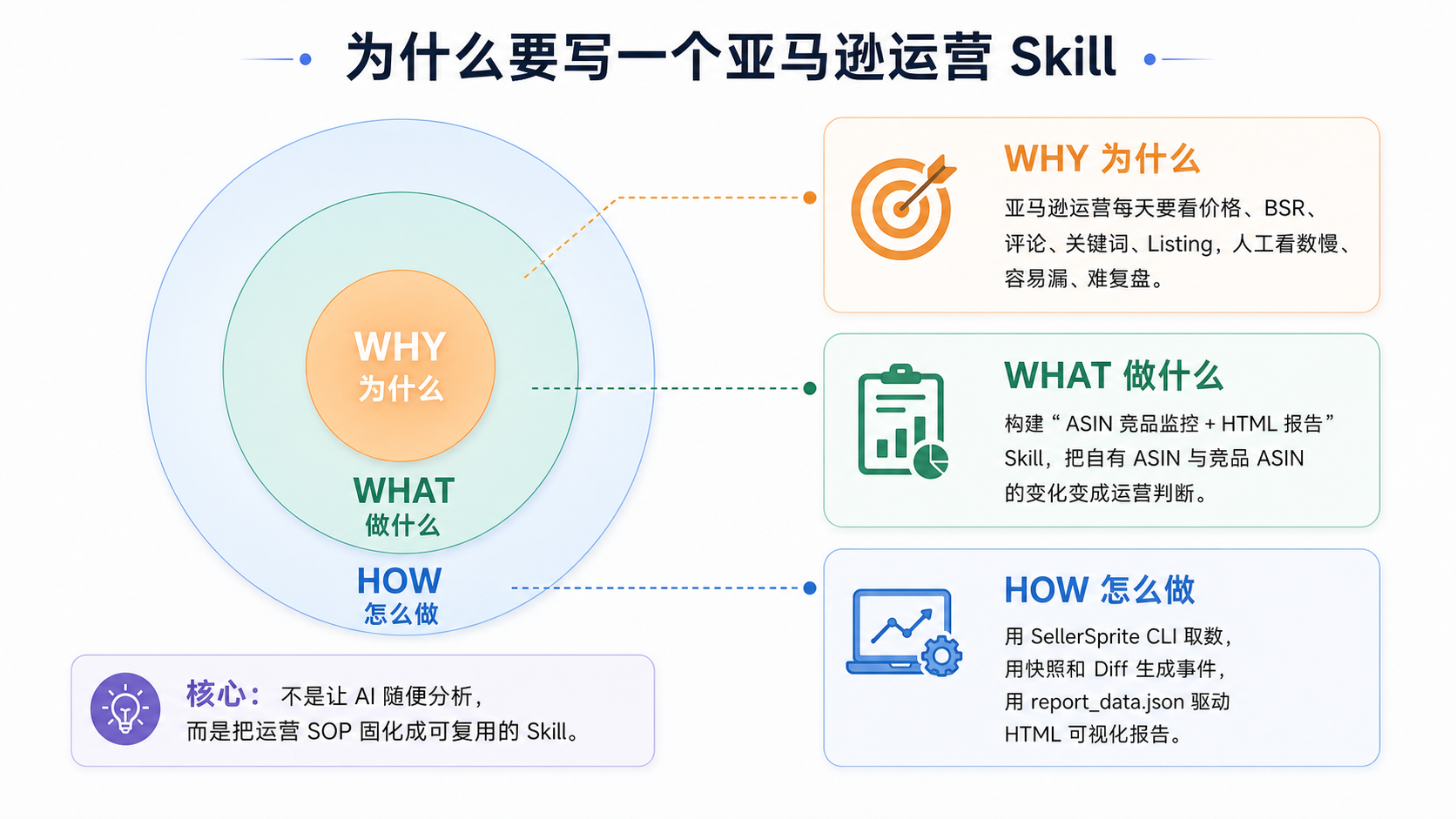
Why:为什么值得做?
假设你做的是亚马逊充电宝类目,手里有 1 个自有 ASIN,旁边有 3 个竞品一直在盯。
你每天真正关心的事情其实不多:
- 竞品有没有降价?
- 有没有突然上 Coupon?
- BSR 是不是变好了?
- 自己的核心词有没有掉排名?
- 差评是不是集中在某个质量问题上?
但麻烦就麻烦在,这些数据不在一个地方。
价格可能看卖家精灵,BSR 可能看 Keepa,关键词排名看 H10,流量分析又在另一个工具里。每个工具都能看一部分,但运营真正要判断的是一整件事:
这个竞品这两天为什么动了?它会不会影响我?我今天要不要跟?
这件事靠人工每天做,问题很明显。
- 太耗时间。几个 ASIN 翻一轮,40 分钟很容易没了。
- 很容易漏。竞品昨天降了 2 美元,今天再看已经不记得原价。
- 复盘困难。没有事件记录,过几天只能翻聊天记录和截图。
- 数据说不清。报告里一堆截图,真要问来源和参数,很难还原。
那么每天重复的盯盘动作固定下来,让AI按照固定SOP去工作,提升的效率就是价值。
What:这个 Skill 到底做什么?
第一版我只让它做一件事:基于 Sorftime CLI,把自有 ASIN 和竞品 ASIN 的变化整理成 HTML 报告。
范围一定要收住。它不是 ERP,不管库存;不是广告后台,不直接优化投放;也不做真实利润核算。它只负责把竞品变化讲清楚。这个点非常重要,边界一定要划分清楚,否则就陷入了无休止消耗 Token 的漩涡。
报告里主要放这几类内容:
| 类别 | 内容举例 |
|---|---|
| 当前状态 | 价格、销量、BSR、评分评论、Coupon、Buybox、Listing 资产、关键词覆盖 |
| 历史趋势 | 近 14/30/60/90 天的销量、BSR、价格、评分变化曲线 |
| 变更事件 | 降价、上券、Listing 改标题、变体调整、断货、新卖家、关键词排名波动 |
| 对比结论 | 自有 ASIN 相比竞品的优势、劣势、风险和机会 |
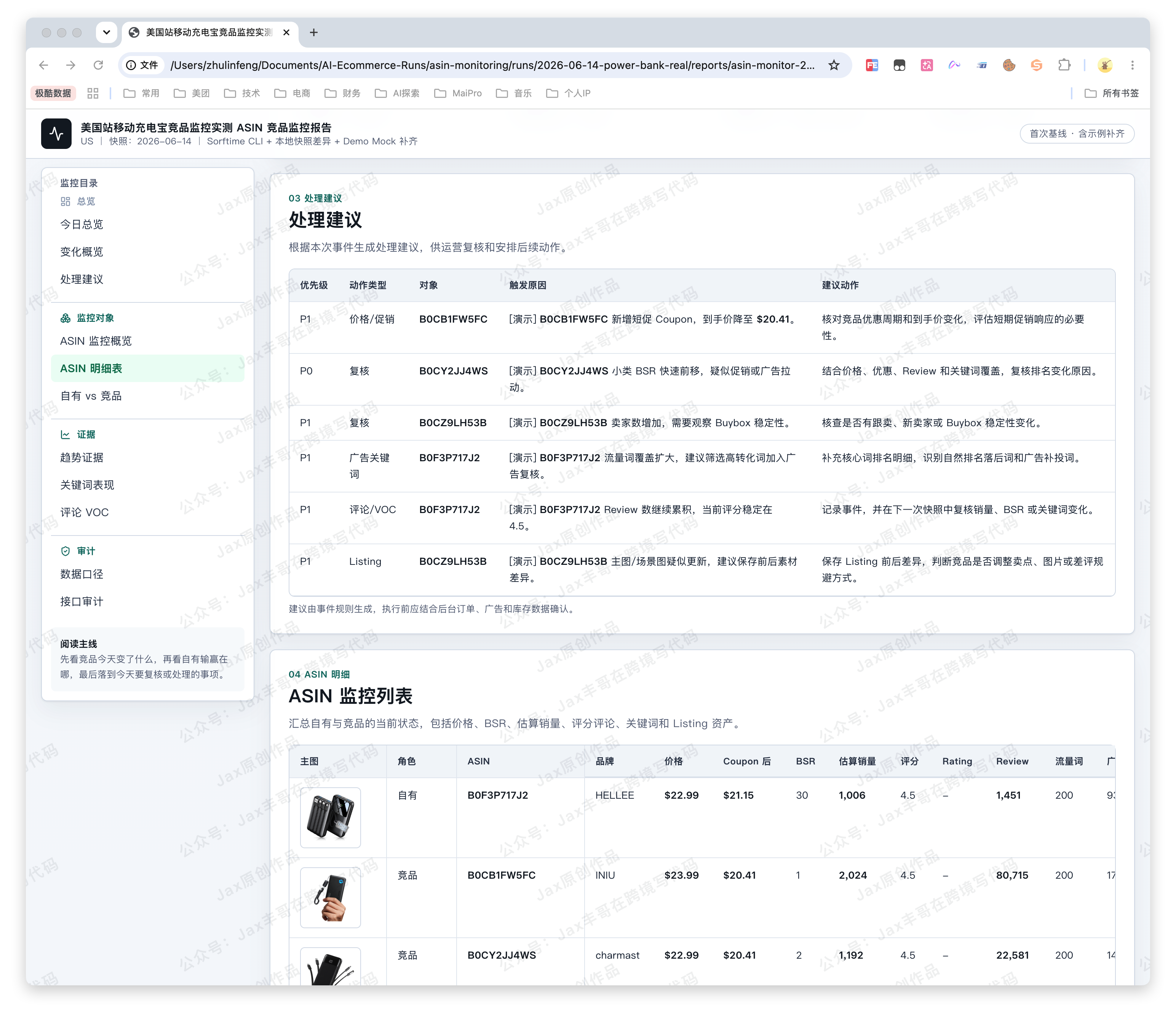
| 运营建议 | 调价、上券、投广告词、优化 Listing、新增竞品监控 |
How:怎么让它稳定?
给 Skill 定规则。很多人会忽略这个原则,所以必须要强调一下,只有在约束条件下AI才会听话,否则就会乱来。因此,必须要在全局中制定一些底线规则。有人会说,我不知道怎么定规则怎么办?没关系,先做到有这个意识,具体的规则可以跟 AI 多几轮讨论,逐渐迭代出逻辑严谨、可以落地执行的规则来。
以下是一个粗浅的示例,可以进行参考:
第一,数据只走一个口径。第一版只用 Sorftime CLI,不混接一堆工具。否则报告看起来很丰富,实际出了问题根本不知道是哪一层口径变了。
第二,流程固定。采集、缓存、快照、快照差异、分析、渲染,每一步都要有输入和输出。AI 可以帮忙判断,但不能随便改流程。
第三,结果可追溯。报告里每个重要结论,都要能查回原始接口、参数和响应文件。
这三条听起来不复杂,但基本决定了这个 Skill 后面能不能被反复使用。
二、把“我想监控竞品”拆细
“我想监控竞品”这句话太宽了。
如果直接丢给 AI,它大概率会给你一套很完整的建议:价格、评论、关键词、Listing、广告、库存、品牌、类目趋势,全都写一遍。看起来没错,但执行不了。
真正做 Skill,要先把它拆成具体场景。
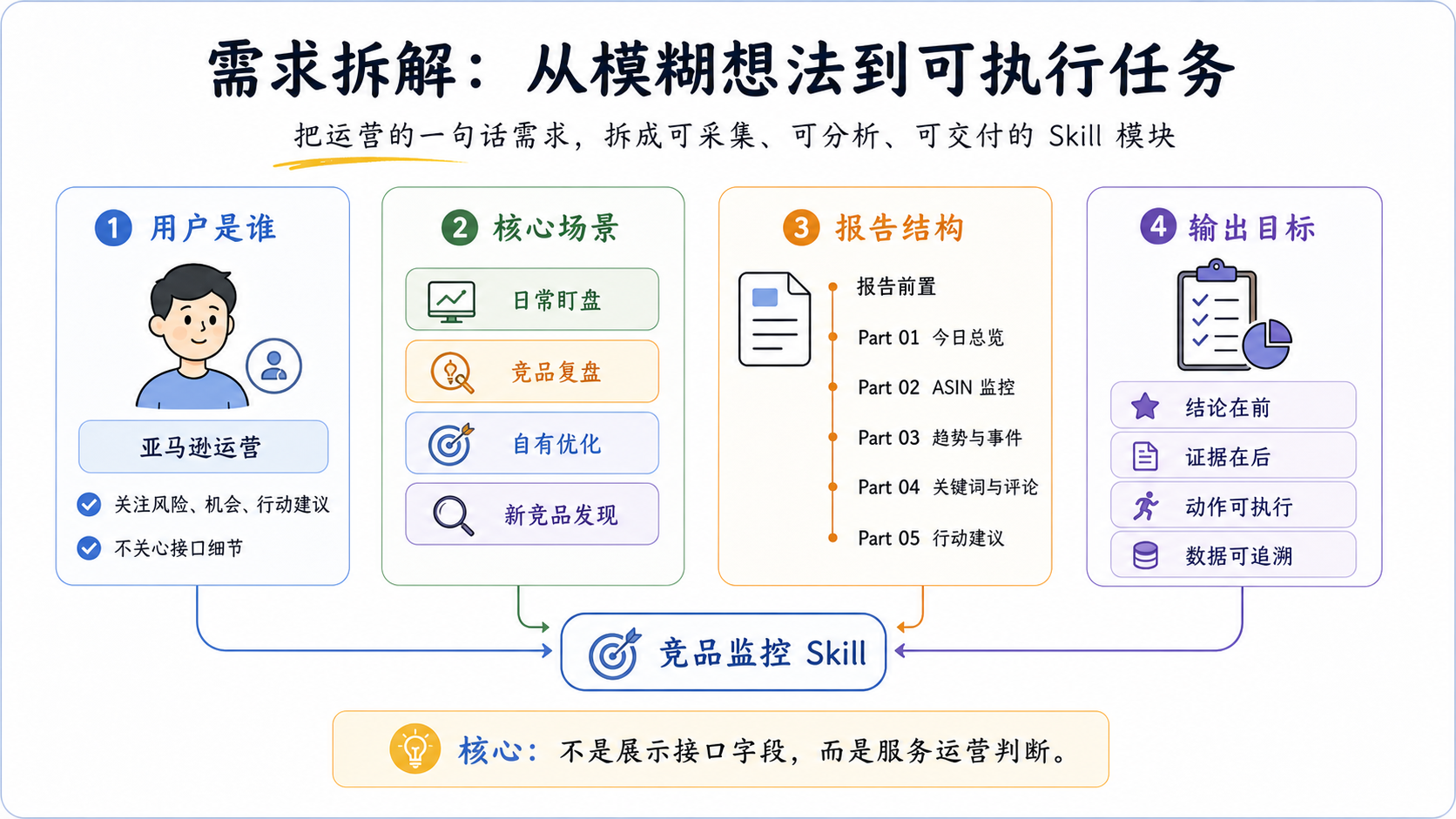
四个最常见的使用场景
我把这个需求拆成四个场景。
第一个是日常盯盘。
每天早上扫一眼:谁降价了,谁上券了,谁 BSR 变好了,自己的核心词有没有往下掉。这个场景不需要长篇分析,重点是快。
第二个是竞品复盘。
某个竞品突然起量,运营会想知道原因。它是不是降价了?是不是同时上了 Coupon?广告词覆盖有没有变多?标题是不是改了?评论有没有明显增长?这些变化要串起来看。
第三个是自有产品优化。
这时候看的不是竞品做了什么,而是自己差在哪里。价格是不是偏高,评论门槛够不够,主图和视频有没有短板,差评里有没有可以反过来做产品改版的点。
第四个是新竞品发现。
比如类目前 100 里有低评论高销量的 ASIN,或者某个新品最近增长很快,又频繁出现在核心词下。这类 ASIN 应该被加进监控列表。
这四个场景拆完之后,报告结构就比较清楚了。
报告目录怎么排?
我最后把报告目录大纲排成这样:
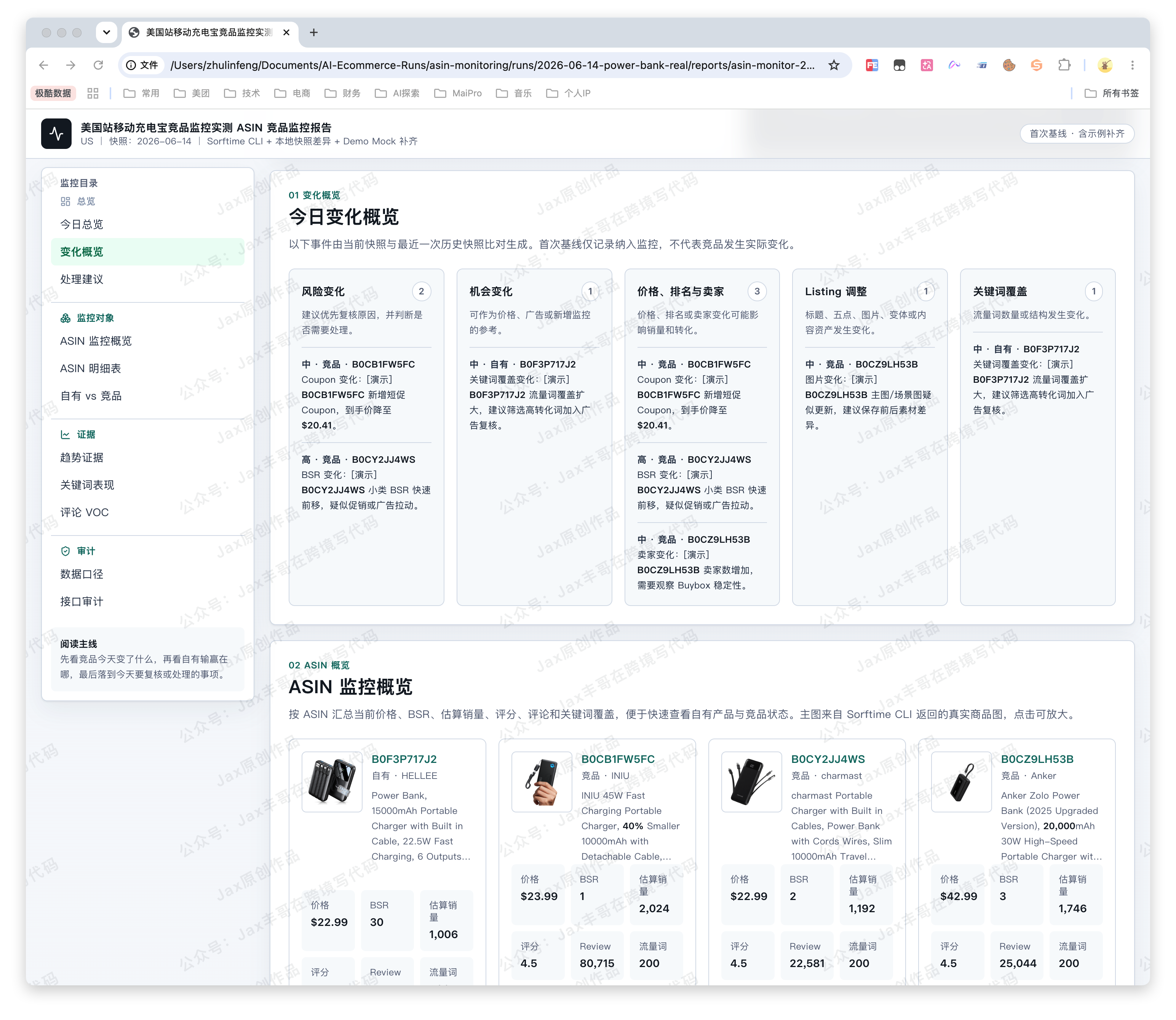
总览(今日总览 + 变化概览 + 处理建议)
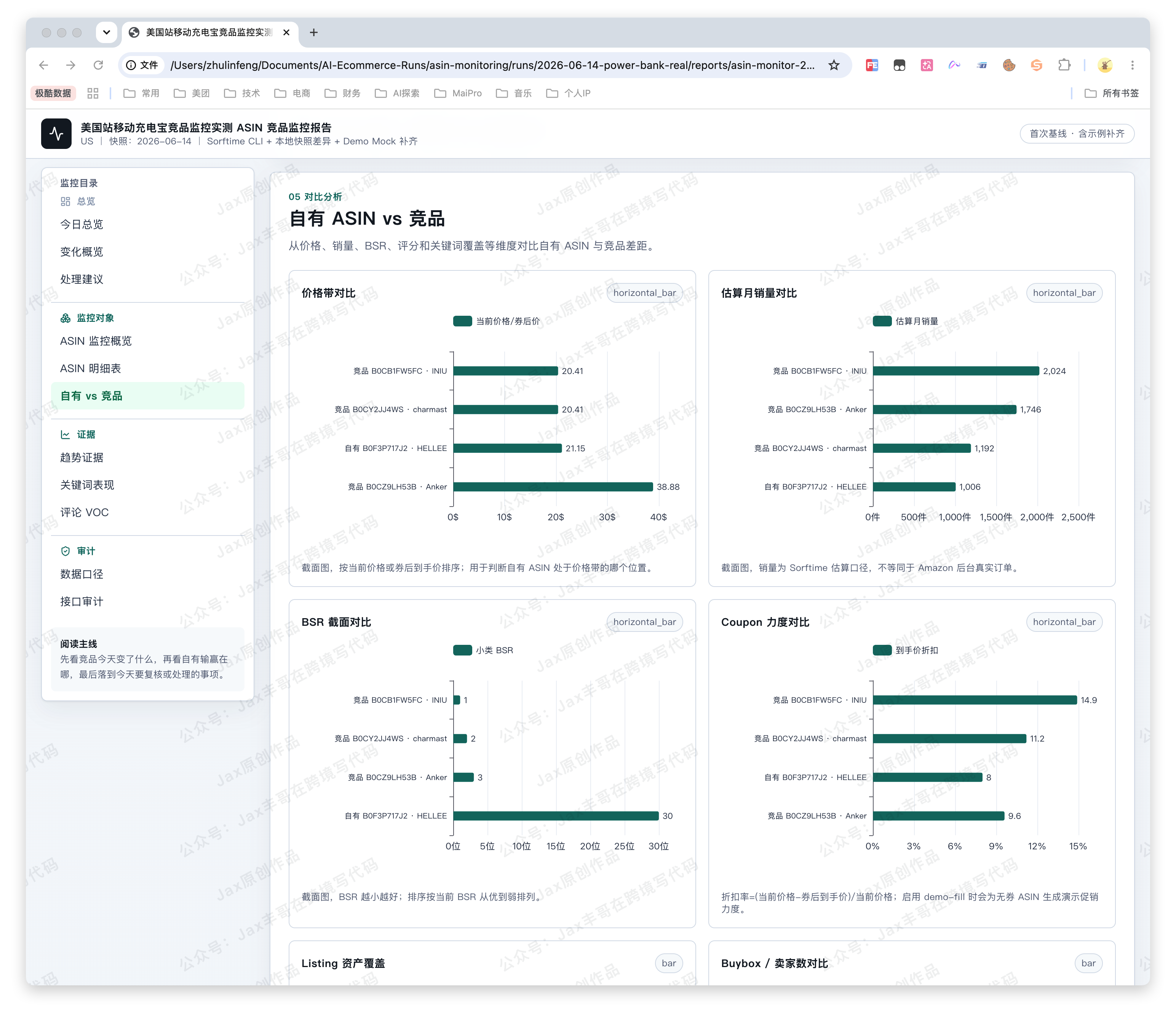
监控对象(ASIN 监控概览 + ASIN 明细表 + 自有 vs 竞品)
证据(趋势证据 + 关键词表现 + 评论 VOC)
审计(数据口径 + 接口审计)三、Skill 到底是什么?
很多人一听 Skill,会以为它就是一段 prompt。我一开始也这么理解。后来真做起来才发现,提示词只是其中很小一部分。一个能稳定工作的 Skill,至少要包括规则、脚本、模板、参考文档和缓存,那下面我们来简单研究一下背后的工作原理。
上一篇我们做过一次简单的解释:Skill 就是一个“高阶版的提示词”,本质上是一个“AI 版本的 SOP”。
比如这个案例,你不用每次都重复说:
帮我分析竞品,要看价格、BSR、评论、关键词、Listing。不要编数据。要标注来源。报告结构固定一点。
你只要说:
帮我生成一份 ASIN 竞品监控报告。
AI 会自己去读这个 Skill 里的规则,按照内置好的SOP流程干活。
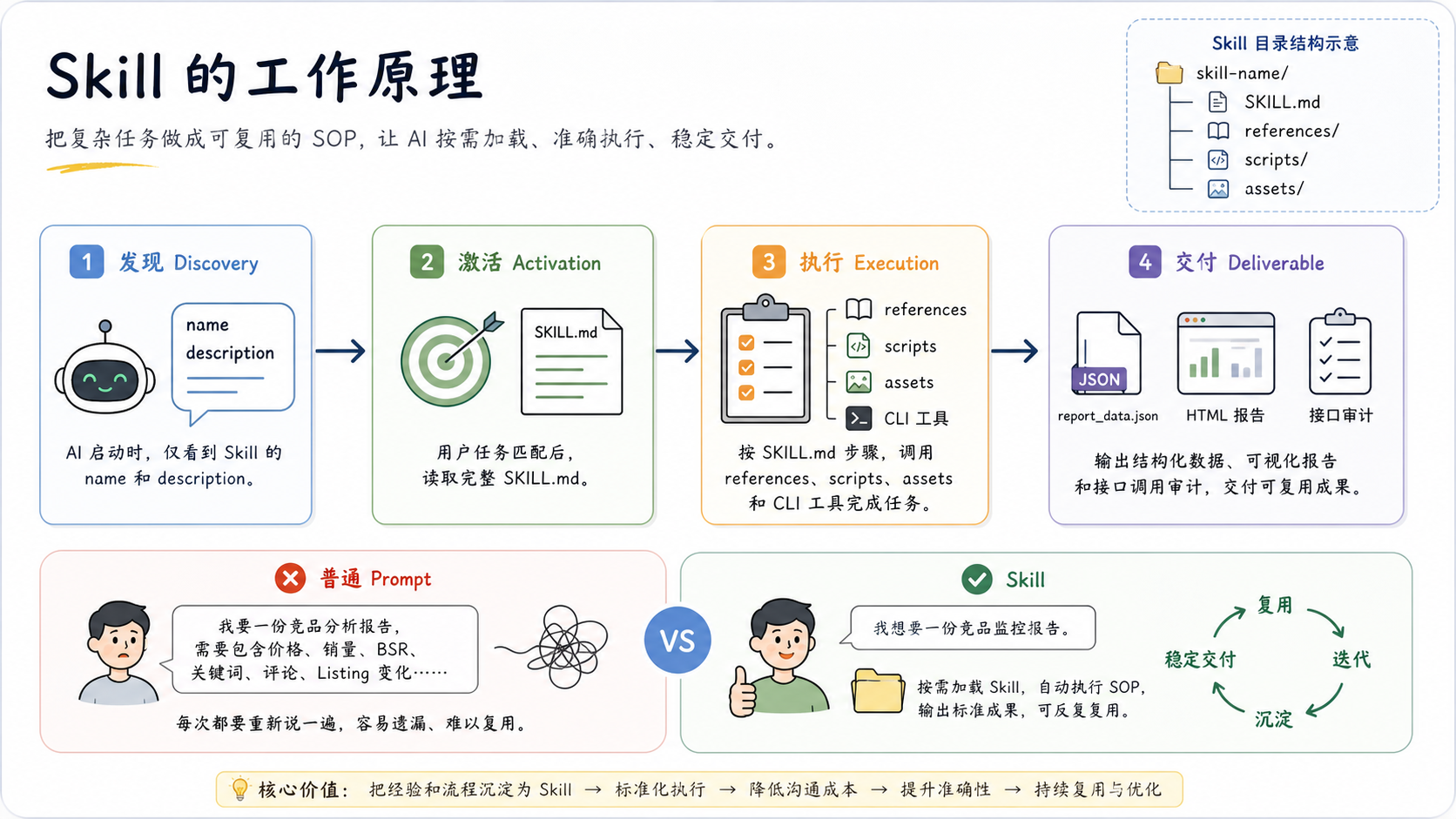
它不是一次性提示词
一个 Skill 被调用时,大概会走四步。
先是发现。
AI 不会一启动就把所有 Skill 全部读完。它会先看每个 Skill 的名字和描述,判断哪个可能适合当前任务。
然后是激活。
当用户的需求匹配上某个 Skill,AI 才会读取完整的 SKILL.md。这里面会写清楚触发条件、执行步骤、禁止事项和交付物。
接着是执行。
到了这一步,AI 会按说明调用脚本、读取参考文档、使用模板、运行 CLI。确定性的事情交给脚本,判断性的部分再让大模型参与。
最后是交付。
在这个 ASIN 监控场景里,最终交付一般是 report_data.json、HTML 报告和接口审计记录。
这里有个点很重要:Skill 的价值不是让 AI “更聪明”,而是让 AI 少一点随机性。
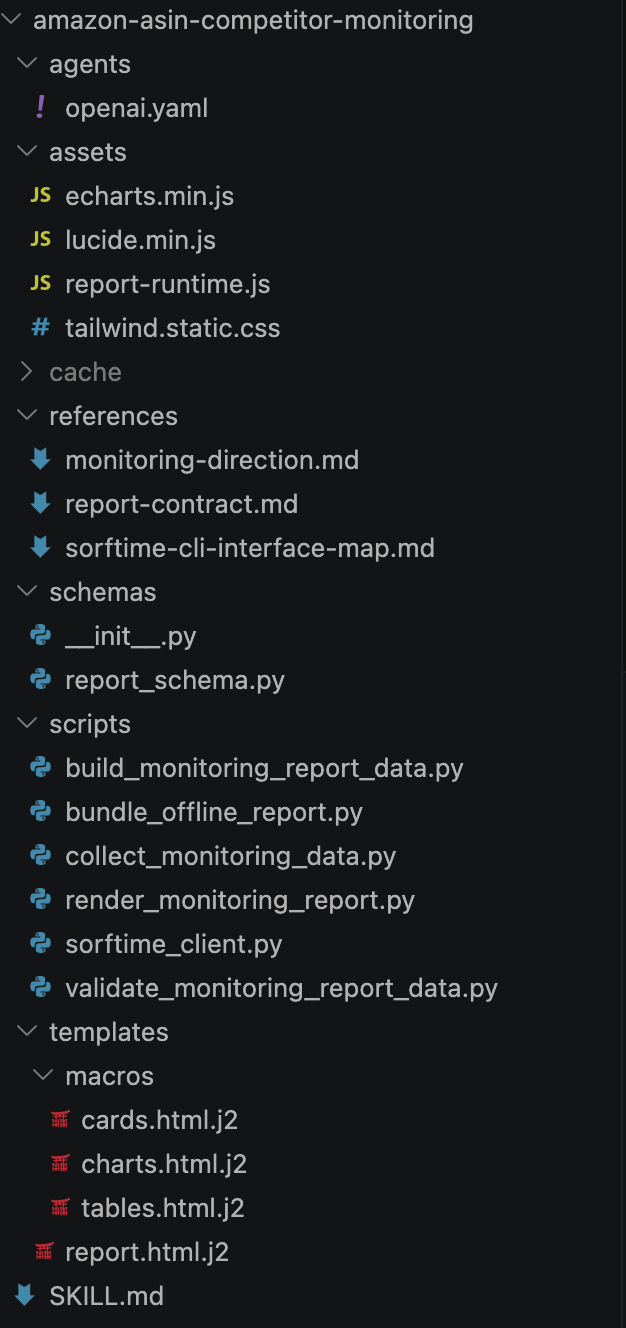
文件夹里放什么?
一个比较完整的 Skill,大概长这样:
amazon-asin-monitor/
├── SKILL.md ← 操作手册:什么时候触发、按什么步骤做、有什么约束
├── scripts/ ← 确定性脚本:采集、加工、校验、渲染
├── references/ ← 参考资料:CLI 文档、字段映射、分析规则
├── templates/ ← HTML 模板:固定骨架,不让 AI 每次自由发挥
├── assets/ ← 静态资源:图表库、样式、图标
└── cache/ ← 运行时产物:原始响应、中间数据我的分工习惯是:
SKILL.md写规则。什么时候触发,先做什么,后做什么,哪些数据不能编。scripts/写确定性逻辑。采集、清洗、快照差异、校验这些,不要交给大模型猜。references/放文档。比如 Sorftime CLI 怎么用,字段怎么解释,哪些指标只能当估算。templates/放报告模板。页面结构固定住,别每次让 AI 重新设计。cache/放运行产物。原始响应、中间数据、历史快照都要能找回来。
这样拆完之后,AI 更像是在执行一套SOP,而不是现场写作文。
四、这个 ASIN 监控 Skill 怎么设计?
回到这次的主角:亚马逊 ASIN 竞品监控。
我给它划的边界很窄:
只基于 Sorftime CLI,把自有 ASIN 和竞品 ASIN 的变化,整理成一份 HTML 报告。
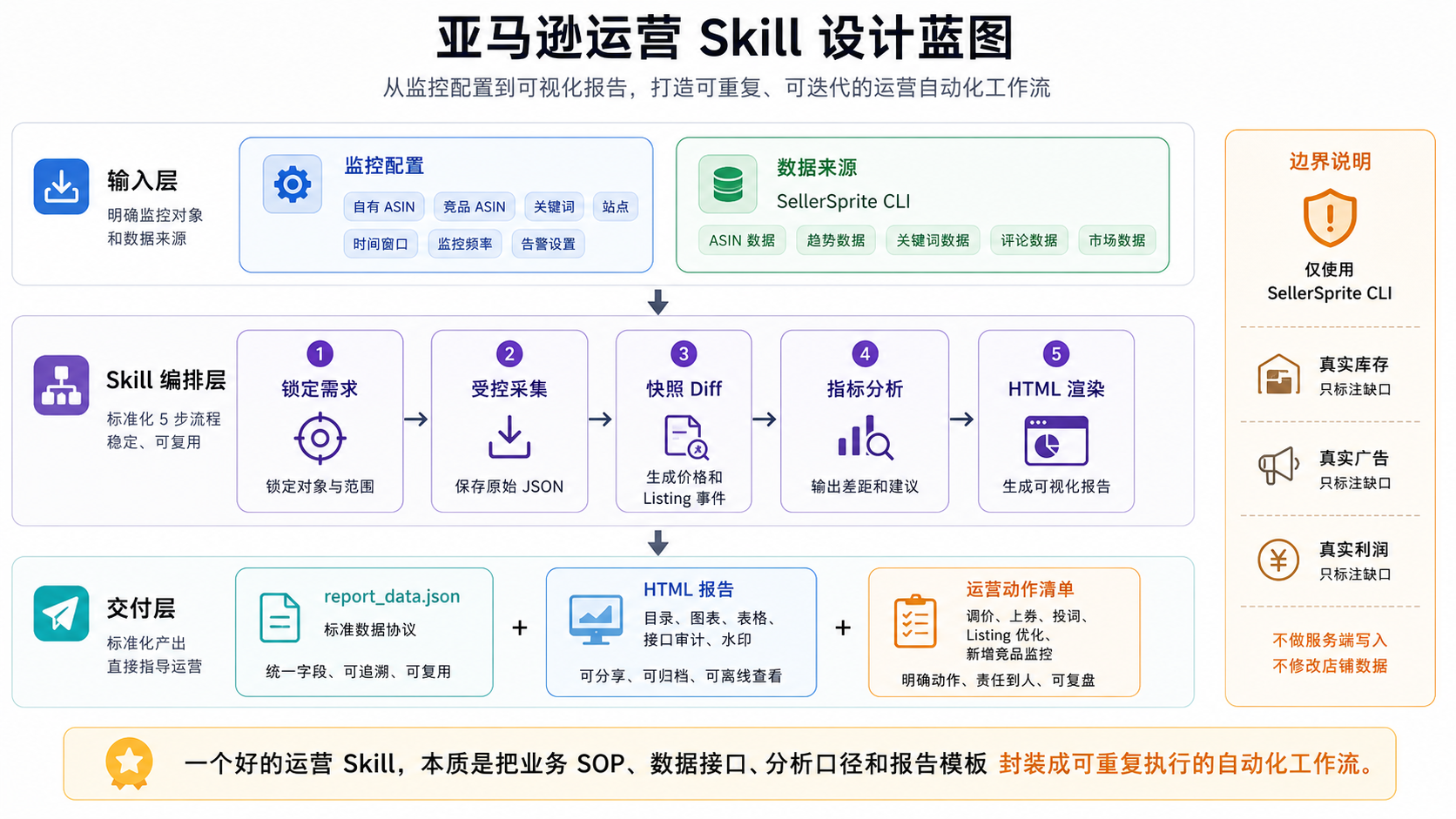
1. 输入层:先把监控对象写死
第一版配置可以很简单:
{
"marketplace": "US",
"own_asins": ["B0OWN001"],
"competitor_asins": ["B0COMP01", "B0COMP02", "B0COMP03"],
"core_keywords": ["power bank", "portable charger"],
"monitor_window_days": [14, 30, 60, 90]
}JSON格式是比较常用的一种格式,方便做定义,如果不熟悉,使用文本描述等其他形式都可以
这里最重要的不是用什么格式定义,而是字段功能定义清楚。
哪个是自己的 ASIN?哪些是竞品?盯哪些关键词?趋势看 14 天还是 90 天?这些东西如果不在输入层写清楚,后面的分析一定会飘。
2. 采集层:第一版只用 Sorftime CLI
Sorftime CLI 能拿到的内容已经够做第一版了。
| 数据类型 | 举例 |
|---|---|
| ASIN 详情 | 价格、评分、评论数、Listing 内容、变体 |
| 产品趋势 | 价格走势、BSR 走势、Buybox 变化、卖家数 |
| 销量预测 | 估算月销量、销售额趋势 |
| 流量词 | 自然排名、广告排名、搜索量、购买率 |
| 出单词 | 优质词、平稳词、流失词、无效曝光词 |
| 评论数据 | 评论原文、星级、VP |
| 市场数据 | 类目 Top100、品牌集中度、卖家集中度 |
3. 快照层:不要只看当前值
只采一次数据,其实只能知道“现在是什么样”。
运营真正关心的是变化。
所以这个 Skill 要每天保存快照,然后比较快照差异。比如:
- 价格从 29.99 降到 25.99,记录为降价。
- 竞品新增 Coupon,记录为促销变化。
- 标题发生变化,记录为 Listing 调整。
- 核心词自然排名从第 8 掉到第 24,记录为关键词流失。
- 差评里频繁出现“发热”,记录为质量预警。
这一步非常关键。没有快照,报告就只能描述现状;有了快照,报告才能讲变化。
4. 分析层:别把事实当结论
“竞品降价了”只是事实,不是结论。
运营真正要判断的是:它为什么降?是短期促销,还是准备打价格战?降价之后 BSR 有没有变好?它有没有同时上 Coupon?我们的价格差距是不是被拉大了?
分析层要做的是把多个事实放在一起看。
比如:
价格下降 + Coupon 上架 + BSR 改善 + 关键词覆盖增加
→ 竞品可能在主动冲量
→ 自有 ASIN 需要评估是否跟券,或者补一部分广告词
这里才是大模型比较适合介入的地方。它不用替你算价格差,也不用替你数排名变化。那些交给脚本就行。它更适合把几个已经确认的事实,整理成运营能理解的判断。
5. 交付层:为什么我选 HTML?
最终报告我没有选 Markdown,而是选了单文件 HTML。
原因很简单:运营要看,团队要讨论,还要归档。
HTML 方便做几件事:
- 左侧目录固定,开会时能直接跳到对应模块。
- 图表可以展示趋势,比截图清楚很多。
- 表格可以排序和对比,适合看多个 ASIN。
- 接口审计可以放在报告底部,需要追溯时能查。
- 文件可以离线打开,丢到群里也能看。
Markdown 适合写过程,HTML 更适合交付。
五、从 0 到 1 怎么做?
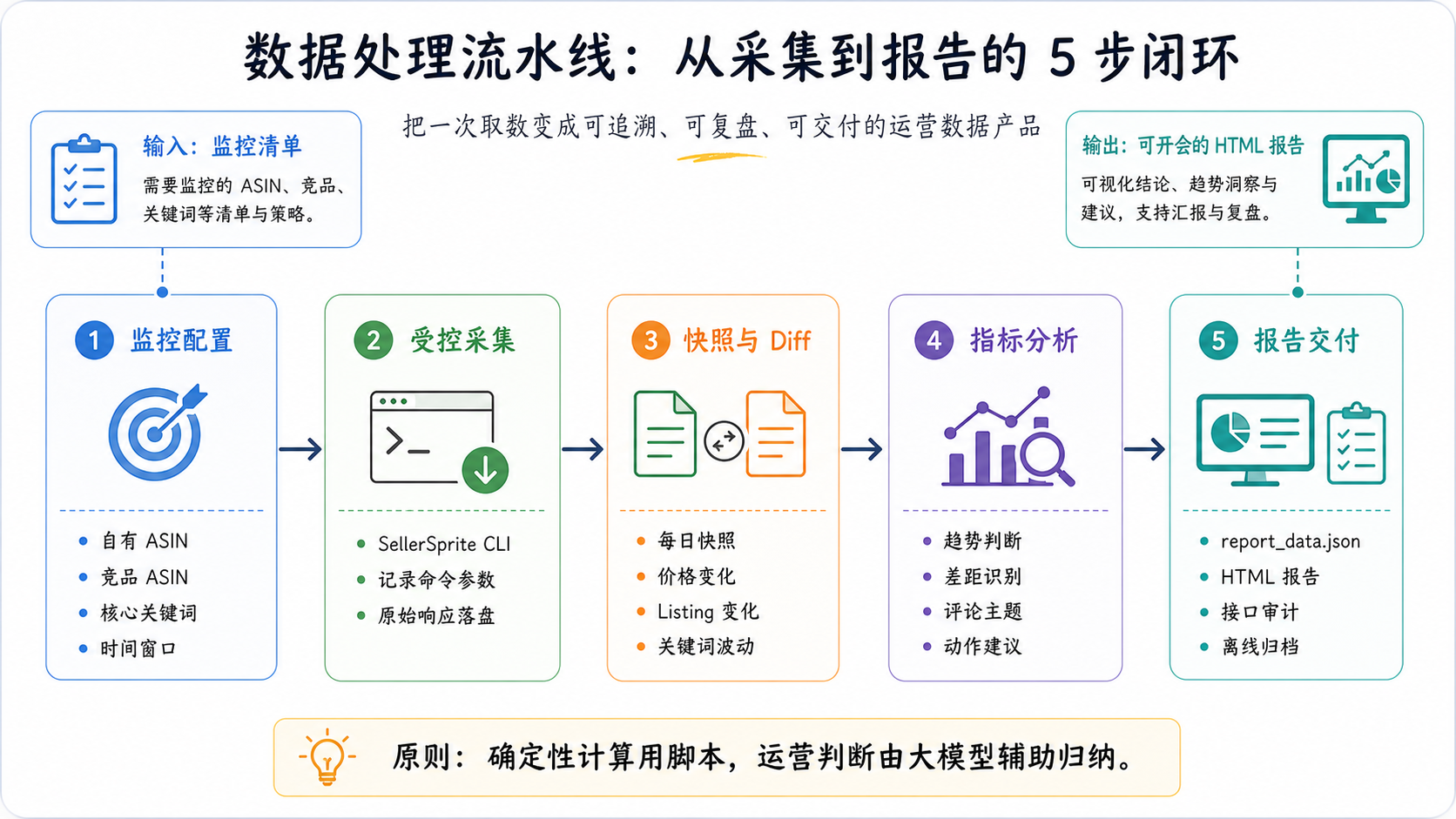
建议按这个顺序来,不要一上来就写代码。结合上述的内容,从业务背景开始着手,先分析,再定框架,尔后圈范围,写规则,最后交给AI落地执行。对AI交付的内容进行验证、纠偏,如此循环最后得到终版。下面我们通过详细的步骤来进行实战演练。
Step 1:先写需求文档
先写一份很朴素的需求文档。
不需要多漂亮,但几个问题要写清楚:
- 谁用?
- 什么时候用?
- 第一版到底交付什么?
- 报告有哪些模块?
- 哪些数据是真实值,哪些只是估算?
- Sorftime CLI 能做什么,做不到什么?
这一步如果省掉,后面很容易越做越散。尤其是大模型参与之后,它很擅长把一个小需求扩写成一整套“看起来很完整”的方案。
Step 2:先定报告目录,再定接口
我建议先设计报告目录,不要先研究接口。
因为报告是给人看的,不是给接口看的。
目录定下来之后,你才知道每个模块需要哪些数据。数据需求明确了,再反推需要调哪些 CLI。这样做出来的报告会更像产品,而不是“我拿到了哪些字段,就展示哪些字段”。
这个顺序很重要。
Step 3:设计 report_data.json
为了保证数据的稳定输出,中间需要加一层标准数据协议,也就是 report_data.json。它相当于采集分析层和页面层之间的合同。
大概长这样:
{
"meta": { "report_date": "2026-06-06", "marketplace": "US" },
"summary": { "risk_count": 3, "opportunity_count": 2 },
"asin_snapshots": [ ... ],
"price_trends": [ ... ],
"keyword_gap": [ ... ],
"review_voc": [ ... ],
"events": [ ... ],
"action_items": [ ... ],
"request_audit": [ ... ]
}为什么要多这一层?
因为 CLI 返回会变,页面模板不应该跟着乱动。只要 report_data.json 稳,HTML 模板就能稳定。
这也是让 AI 输出稳定的关键之一:别让它每次都面对一堆原始 JSON 自己理解。
Step 4:写采集脚本
采集脚本做的是编排,不是重新造一套 CLI。
页面不要直接吃 CLI 的原始返回!!!这个细节非常非常重要, AI 对话中他读了返回结果就会浪费很多 Token。所以,采集的数据直接通过脚本保存到硬盘或者数据库,这种方式可以避免 AI 读不需要读的数据。
脚本主要负责:
- 读取监控配置
- 调用 Sorftime CLI
- 记录真实命令和参数
- 保存原始请求和响应
- 做缓存去重
- 失败时及时停下来
- 更新接口调用清单
我不建议把采集逻辑写得太“聪明”。脚本越确定越好。该失败就失败,该记录就记录。不要静悄悄吞掉错误,更不要在数据缺失时让 AI 自己补。
Step 5:写分析脚本
分析脚本把原始数据变成可用事实。
比如:
- 当前快照
- 历史趋势
- 快照差异事件
- 关键词差距
- 评论主题
- Listing 健康度
- 处理建议
这里要分清两类事情。
排名变化、价格差值、搜索量排序,这些是确定性计算,交给脚本。
竞品意图、评论主题归纳、运营建议,这些有判断成分,可以交给大模型,但前提是它只能基于已采集到的数据说话。
Step 6:固定 HTML 模板
不要每次让大模型重新写 HTML。
模板一旦固定,页面结构就固定。后面变化的只是数据。
这件事对稳定性影响很大。很多人觉得 AI 报告不稳定,其实不是分析不稳定,而是交付格式每次都在变。今天是列表,明天是卡片,后天又变成一堆大段文字。
模板固定后,报告才像一个产品。
Step 7:最后一定要校验
校验这一步很无聊,但必须做。
至少要检查:
- 需要的数据是否完整
- 逻辑是否有偏离
- HTML 能不能离线打开
- 图表是否正常渲染
- 接口审计有没有生成
- 有没有调用不该调用的接口
- 等等等
没有校验的 Skill,演示时可能很好看,真实用几次就会暴露问题。
六、什么样的 Skill 才算好?
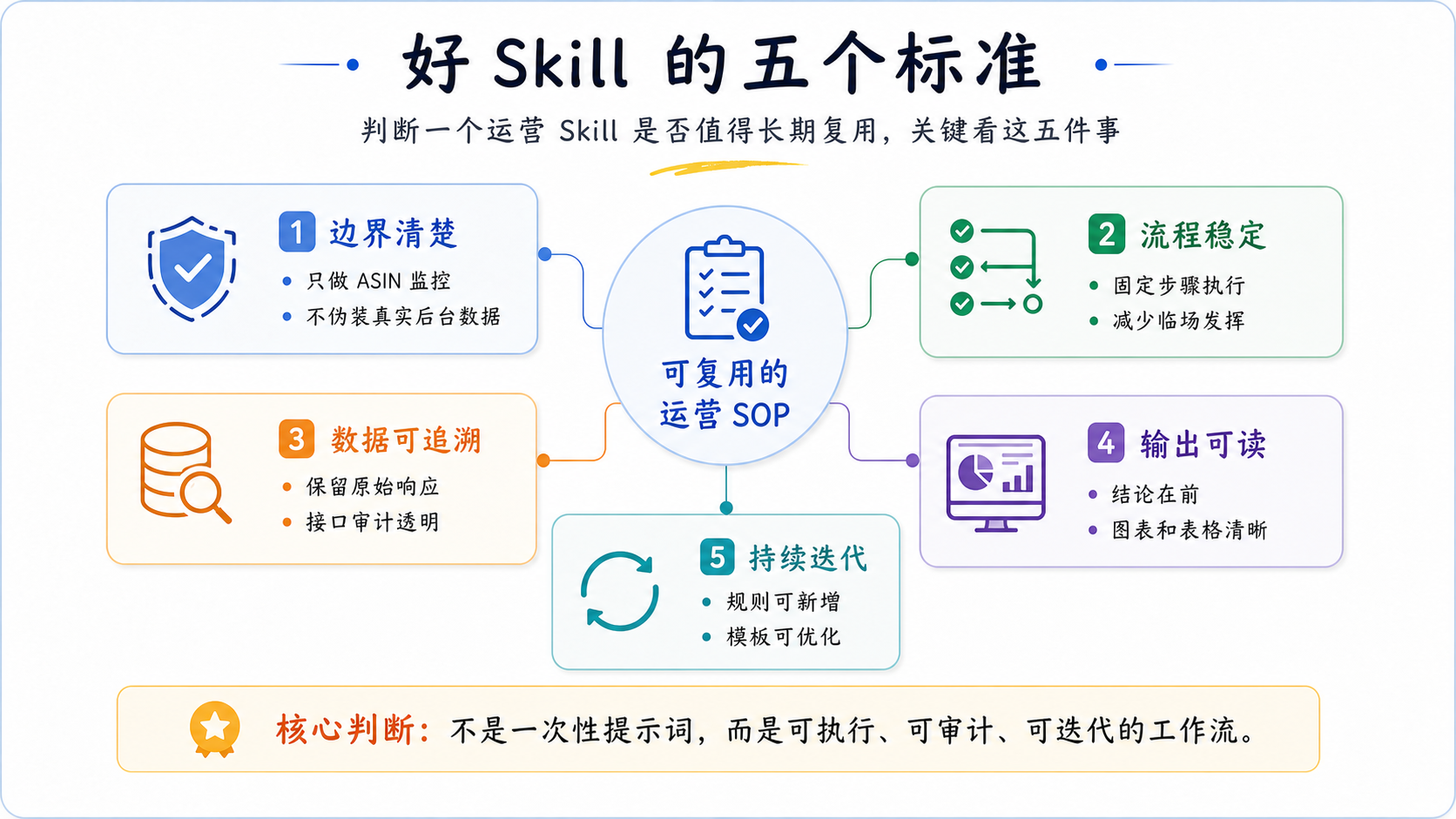
我自己判断一个 Skill 好不好,主要看这几个点。
1. 边界清楚
第一版不要什么都做。
这个 ASIN 监控 Skill 就只做三件事:Sorftime CLI 口径、竞品变化监控、HTML 报告。
不做自动调价,不做广告后台优化,不做真实库存,不做真实利润。
边界收住,结果才稳。
2. 流程稳定
每次执行都应该走同一套流程:
锁定需求 → dry-run 审计 → 采集 → 构建数据协议 → 校验 → 渲染 → QA
如果每次都靠 AI 自己想步骤,那它更像临时帮你跑了一次任务,不像 Skill。
3. 数据能追溯
报告里每个重要结论,都要能往回查。
哪个接口来的?参数是什么?响应文件在哪里?有没有缓存命中?这些东西看着琐碎,但决定了团队敢不敢信这份报告。
4. 输出真的能看
Skill 最后不是为了生成一堆 JSON,而是为了让人做决策。
所以报告要照顾阅读顺序:先结论,再证据,再行动。图表、表格、事件线都要服务这个目的。
5. 后面改得动
第一版一定不会完美。
今天你可能想新增一个“竞品上券事件”,明天想补一个“关键词流失模块”,后天又觉得 HTML 里的趋势图不够清楚。
好的 Skill 应该能在原结构上迭代,而不是每改一次就推倒重来。
七、写在最后
做完这个 Skill 之后,我最大的感受是:在跨境电商运营里,AI 真正有用的地方,不是替运营拍脑袋做判断,而是把那些重复、琐碎、需要按步骤执行的工作跑稳,能落地以前只有依赖技术人员才能完成的工具。
虽然有了工具,运营还是要负责方向。
比如要不要跟价,要不要加广告,要不要改 Listing,这些判断不能甩给 AI。AI 更适合做的是:把数据拉回来,把变化找出来,把证据整理好,把报告交付出来。
所以一个好用的运营 Skill,本质上是把几件东西装在一起:
- 业务 SOP
- 数据接口
- 分析口径
- 报告模板
- 校验和审计
你只要先把人的工作流程写清楚,再把确定性的部分交给脚本,把需要归纳的部分交给大模型,最后用固定模板交付。
这样做出来的东西,才有机会从“试一次挺惊艳”,变成“每天都能用”。
以上就是本次 Skill 从0到1的实战,文中展示的报告并非完美,一些图表逻辑也并非严谨,只是抛砖引玉,这个构建的思路和过程才是真正有价值的。


